Denoising Diffusion Probabilistic Models (DDPM) — From Noise to Crystal-Clear Images
A step-by-step guide to understanding how DDPMs learn to generate images by mastering the art of denoising
Let us start with a simple thought experiment. Imagine you have a beautiful photograph of a cat. Now, suppose someone starts corrupting this image — at each step, they add a tiny bit of random static noise to every pixel. After one step, the image looks almost the same. After ten steps, it looks slightly grainy. After a hundred steps, the cat is barely recognizable. And after a thousand steps, all you see is pure, meaningless static — like the snow on an old television screen.
Now here is the interesting question: Can you learn to reverse this process? Can you take that pile of random noise and, step by step, reconstruct the original cat photograph?
This is exactly what Denoising Diffusion Probabilistic Models (DDPMs) do. The idea was formalized by Ho, Jain, and Abbeel in their landmark 2020 paper, and it has since become one of the most influential frameworks in generative AI.
The core idea is beautifully simple:
- Forward process: Systematically destroy an image by adding noise over many small steps until nothing remains but pure Gaussian noise.
- Reverse process: Train a neural network to undo each step of noise addition, learning to progressively reconstruct the original image from noise.
If the network learns to reverse each tiny step of corruption, then we can start from pure random noise and generate entirely new images that look like they came from the training data.
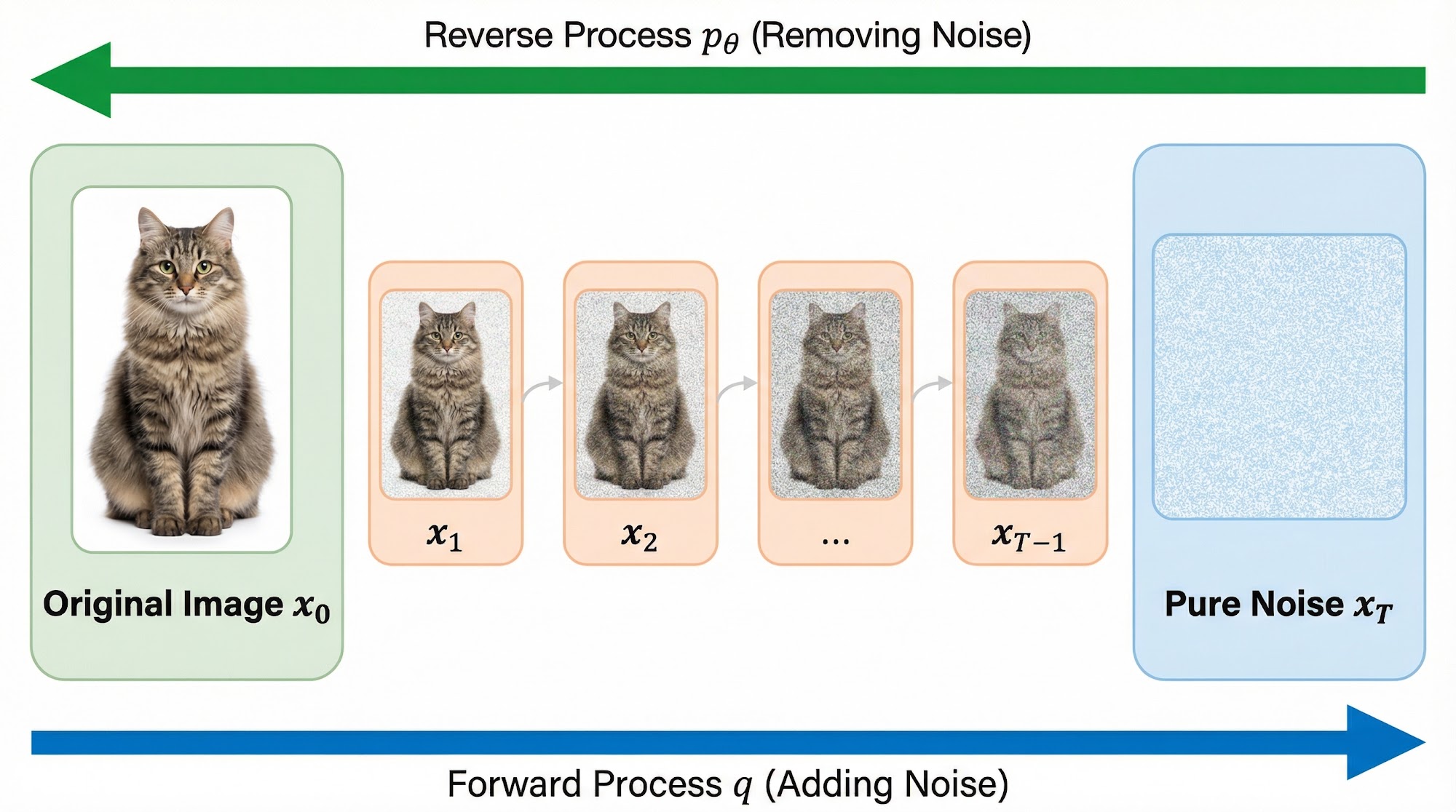
Let us now understand each of these processes in detail.
The Forward Process — Destroying Images Systematically
Let us begin by understanding how we systematically destroy an image. The forward process takes a clean image and gradually adds Gaussian noise to it over T time steps.
At each step t, we take the image from the previous step and add a small amount of noise. The mathematical representation for a single step is:
What does this mean? For each pixel, we sample from a Gaussian distribution where:
- The mean is the previous pixel value scaled down by a factor of
- The variance is
The parameter is called the noise schedule. It controls how much noise is added at each step. Typically, starts small (e.g., ) and increases linearly to a larger value (e.g., ).
Let us plug in some simple numbers to see how this works. Suppose we have a single pixel with value , and at this time step .
The mean of the Gaussian is .
The variance is , so the standard deviation is .
So the new pixel value is sampled from . Notice how the mean has shrunk slightly (from 0.8 to 0.796) and we have added a small amount of random noise. After many such steps, the pixel value will drift towards zero and the noise will dominate. This is exactly what we want.

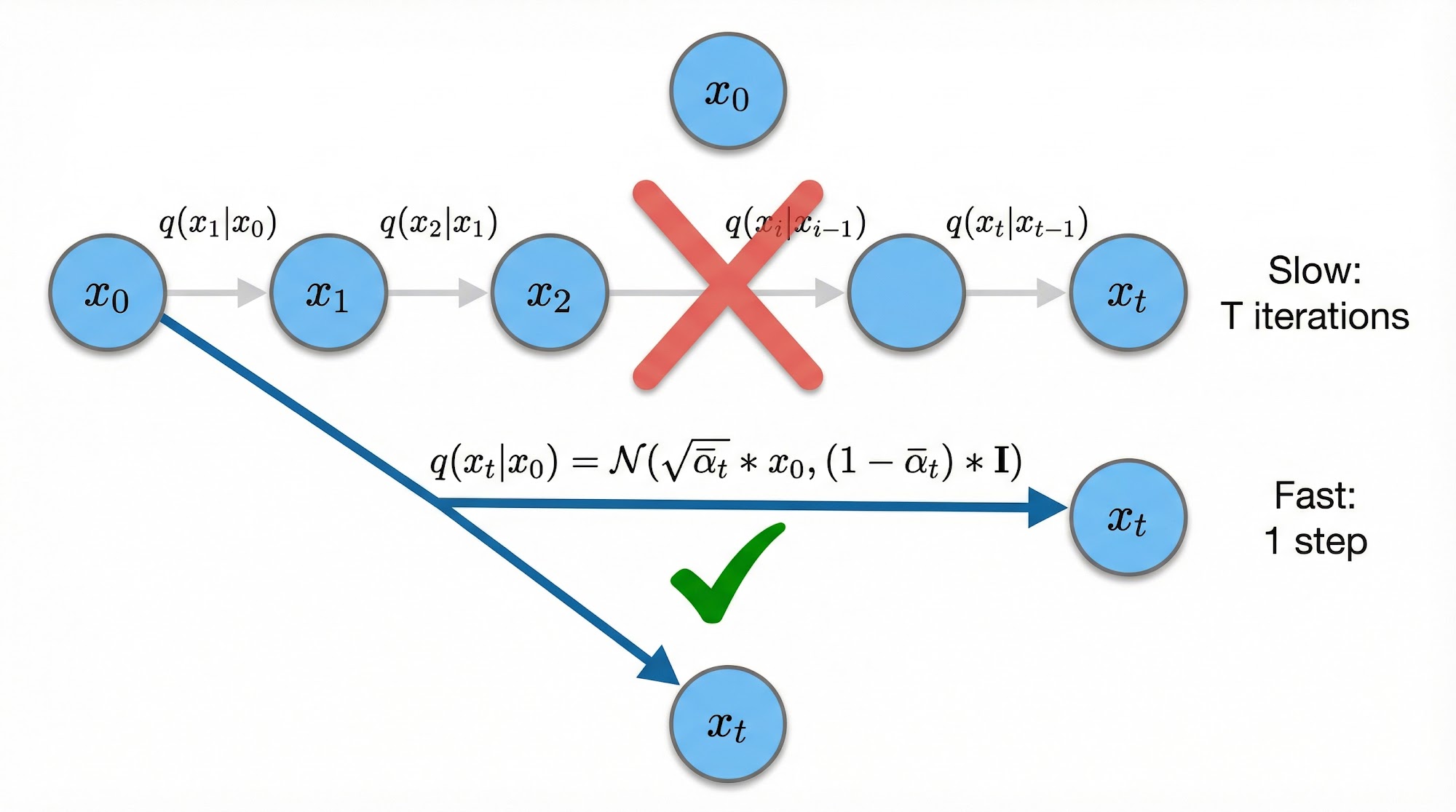
Now, here is a clever mathematical trick. For convenience, let us define and . Using these definitions, we can derive a closed-form expression that lets us jump directly from the original image to any noisy version in a single step:
This means we can write:
This is extremely important for training, because we do not have to iteratively add noise T times — we can jump to any noise level in one step.
Let us plug in some numbers. Suppose (which means about half the original signal is preserved) and our pixel value is . If we sample from a standard Gaussian:
At , about 70.7% of the original signal remains and 70.7% of the noise is mixed in. As decreases towards zero (at later time steps), the noise completely takes over. This makes sense because the forward process should eventually destroy all structure in the image.
The Reverse Process — Learning to Denoise
Now let us come to the main character in our story: the reverse process.
Our goal is to start from pure noise and progressively remove noise until we get a clean image. To do this, we need to learn the reverse transition .
But here is the problem: computing directly is intractable. It would require integrating over all possible original images, which is impossible.
However, there is a beautiful result. If we also condition on the original image , the posterior becomes tractable. It turns out that is a Gaussian distribution with a known mean and variance:
where the mean is:
and the variance is:
Let us plug in some concrete numbers to understand this. Suppose at time step (out of ), we have , , , . If (original pixel) and (current noisy pixel):
The coefficient of is
The coefficient of is
So
This tells us that the true reverse step mostly relies on the current noisy image (with coefficient 0.985) and only slightly uses the original image (with coefficient 0.0142). This makes intuitive sense — at intermediate noise levels, the noisy image still contains a lot of useful information.
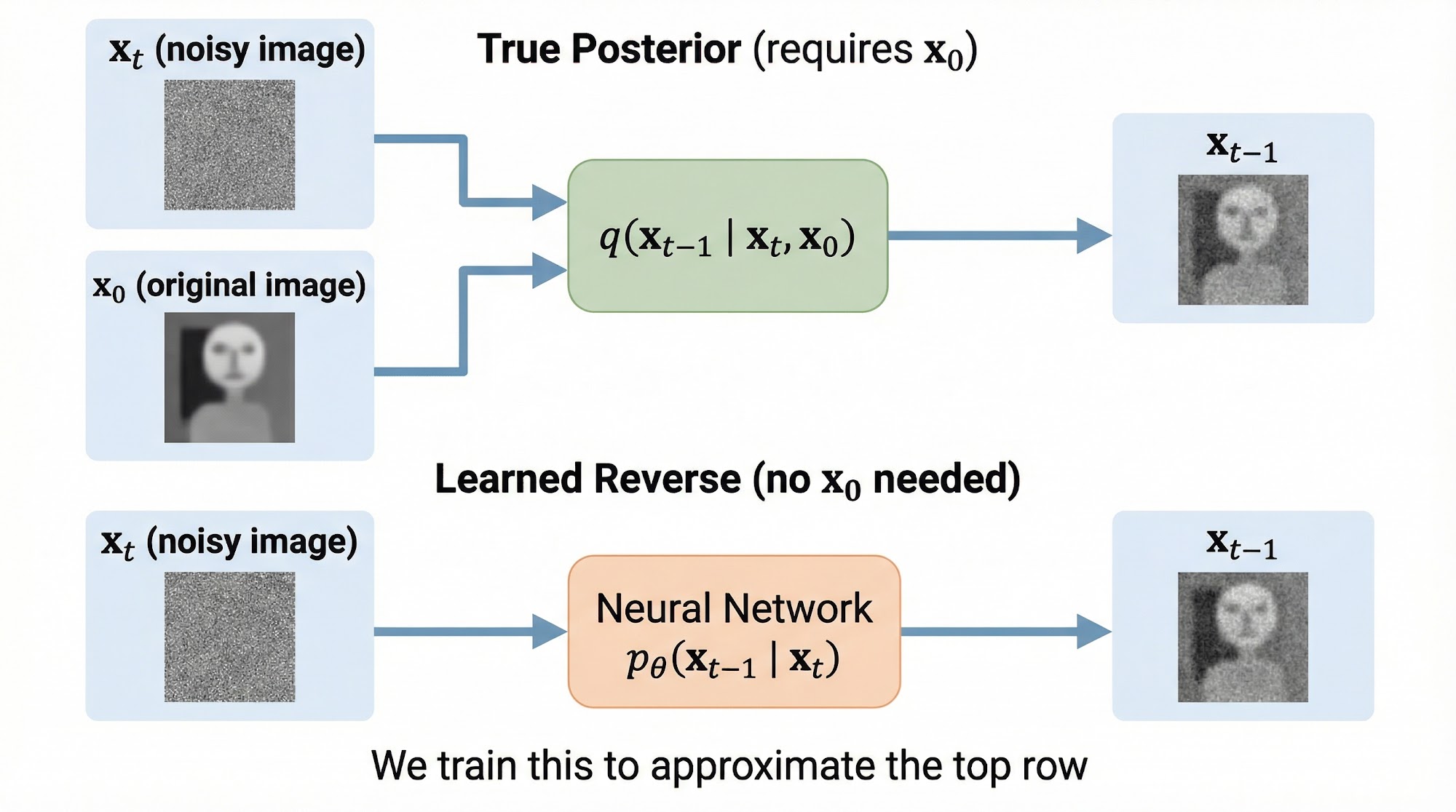
But wait — during generation, we do not have access to ! That is the whole point: we are trying to generate new images, so we cannot condition on the original.
This is where the neural network comes in. We train a model to approximate the reverse process:
The model outputs a predicted mean , and we fix the variance to be either or (both work well in practice). The model takes as input the noisy image and the timestep , and it learns to predict what the slightly less noisy image should look like.
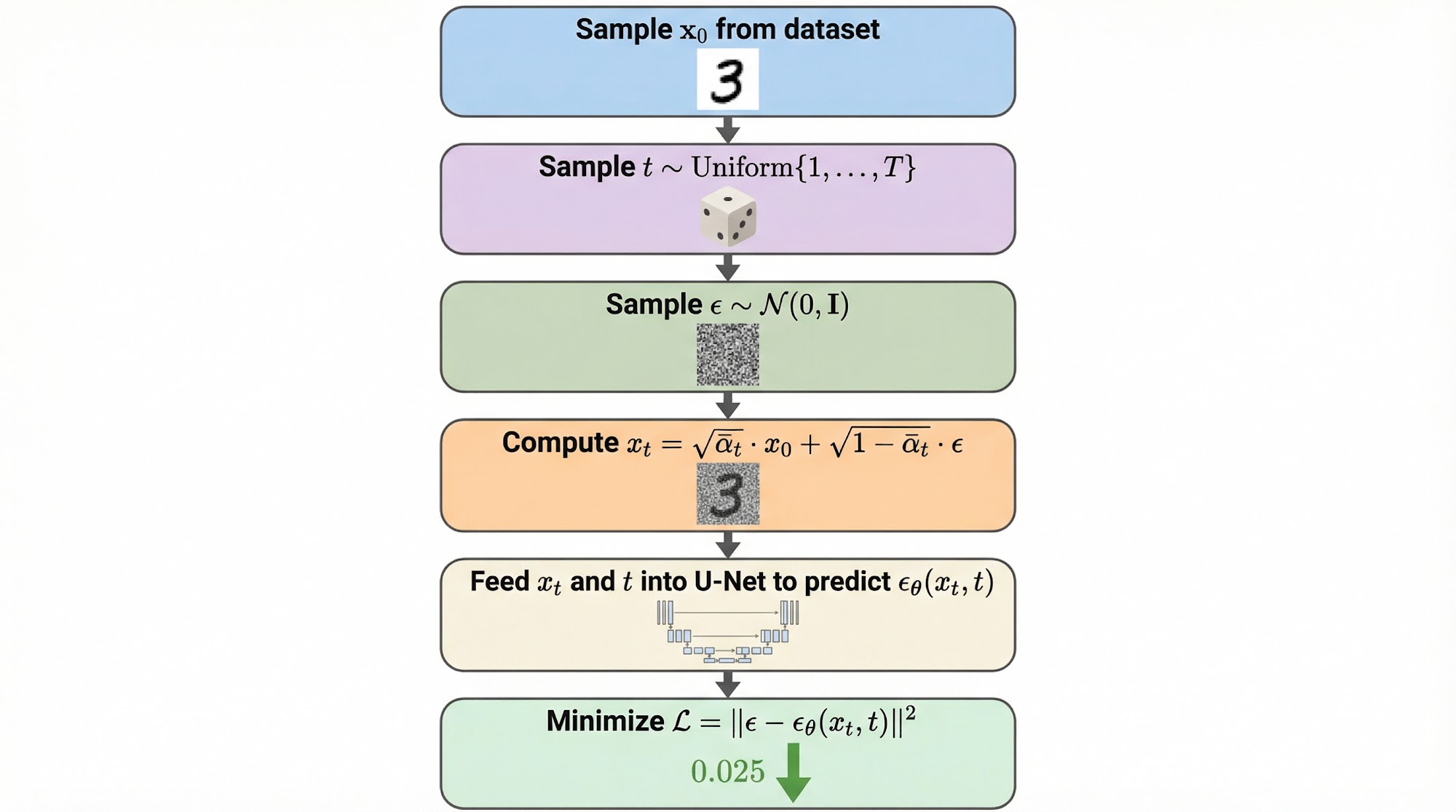
The DDPM Loss — Predicting the Noise
Now the question is: How do we train this neural network?
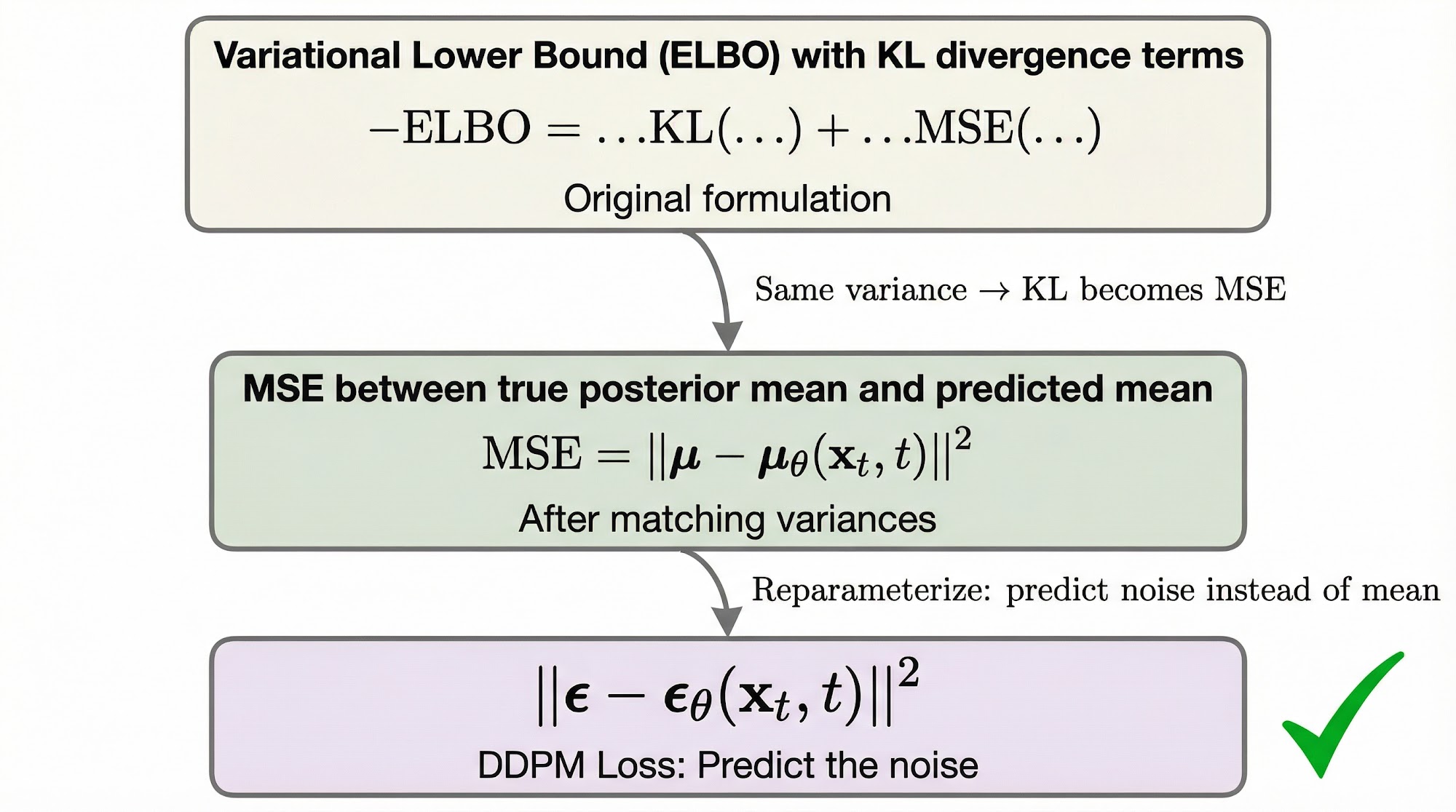
We start from the variational lower bound, just as we did for VAEs. The evidence lower bound (ELBO) for diffusion models decomposes into three types of terms:
- Reconstruction term: How well the model reconstructs from
- Prior matching term: How close is to the standard Gaussian — this is fixed by design
- Denoising matching terms: For each step , the KL divergence between our model and the true posterior
The DDPM paper focuses on the third set of terms. Since both distributions are Gaussians with the same variance, the KL divergence reduces to a simple mean squared error between their means:
This makes sense — we are penalizing the model whenever its predicted mean deviates from the true posterior mean. The closer the two means are, the better our reverse process matches the true one.
But here comes the key insight of the DDPM paper. Recall that we can write in terms of and the noise using our closed-form expression:
If we substitute this into the true posterior mean and reparameterize the model to predict the noise instead of the mean directly, the loss simplifies dramatically to:
This is the final DDPM training objective, and it is remarkably simple: train the network to predict the noise that was added to the image.
Let us plug in numbers to see why this works. Suppose we added noise to a pixel, and our network predicts . The loss for this pixel is . If the network perfectly predicts the noise, the loss is zero. The network learns to look at a noisy image at any noise level and figure out exactly what noise was added. This is exactly what we want.
The U-Net Architecture — The Noise Predictor
Now that we know what to train, the question is: What neural network do we use?
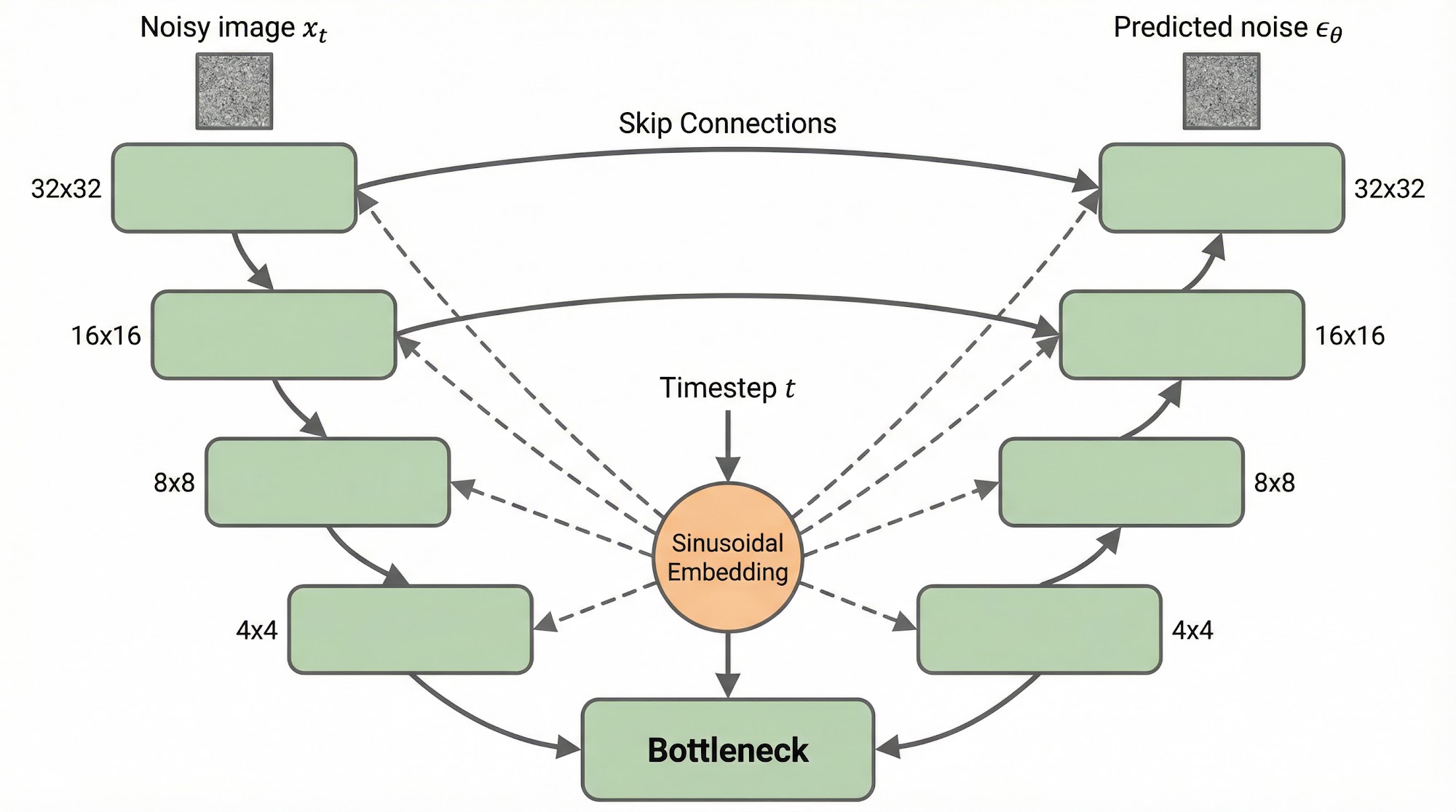
The DDPM paper uses a U-Net architecture, which was originally designed for image segmentation. The U-Net is an excellent choice for this task because it processes images at multiple resolutions while preserving fine spatial details through skip connections.
The U-Net has three main components:
-
Encoder (downsampling path): A series of convolutional blocks that progressively reduce the spatial resolution while increasing the number of channels. This captures high-level features.
-
Decoder (upsampling path): A series of convolutional blocks that progressively increase the spatial resolution back to the original size. This reconstructs the spatial details.
-
Skip connections: Direct connections between encoder and decoder layers at the same resolution. These allow the decoder to access fine-grained spatial information that would otherwise be lost during downsampling.
There is one additional input that the U-Net needs: the timestep . The model must know which noise level it is denoising, because the denoising strategy at (very noisy) is very different from (mostly clean). The timestep is encoded using sinusoidal position embeddings — the same technique used in Transformers — and injected into each layer of the network.
Sampling — Generating Images from Noise
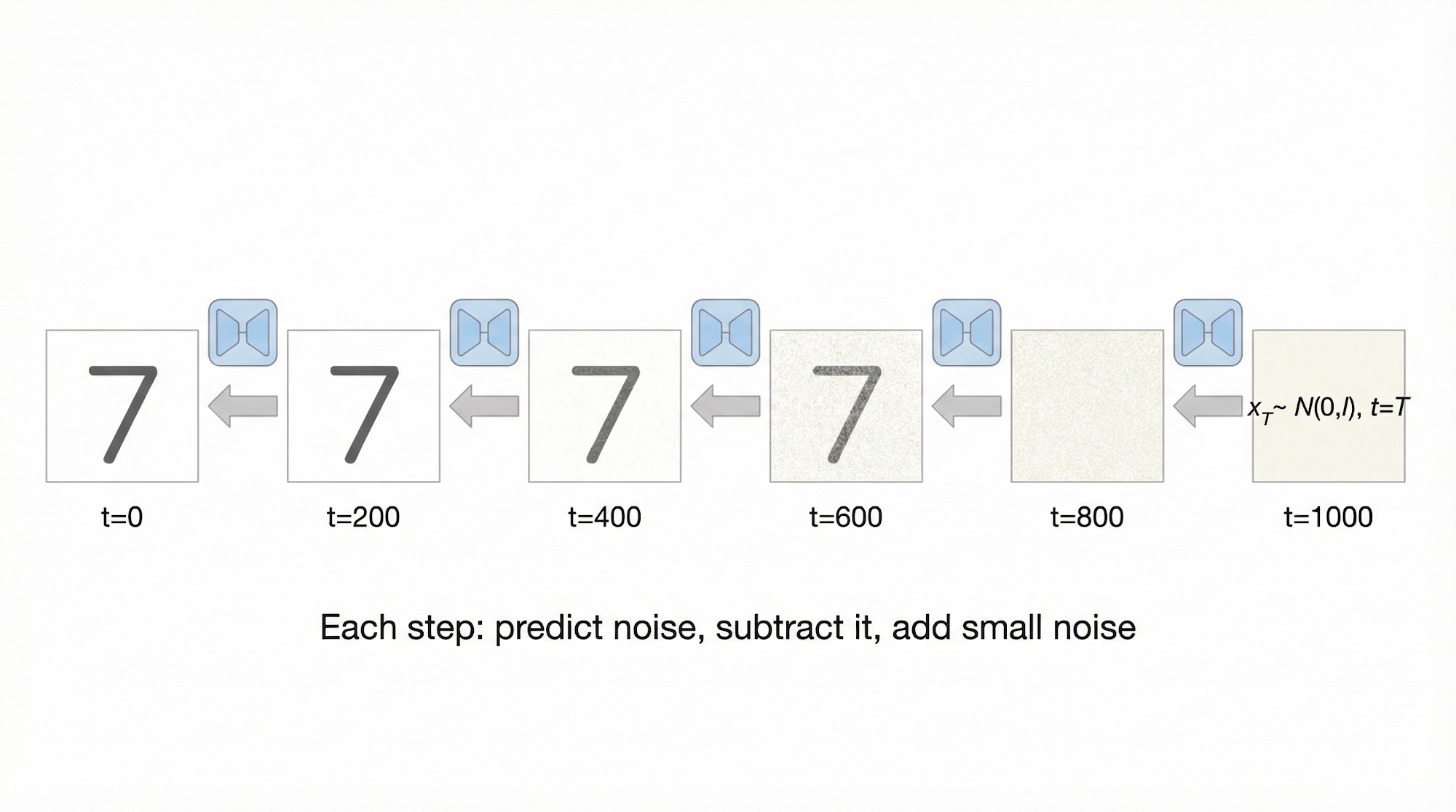
Now let us understand how we generate images once the model is trained.
The sampling process starts from pure Gaussian noise and iteratively denoises it for steps. At each step, the model predicts the noise, and we use this prediction to compute a slightly less noisy image.
The sampling update rule is:
where and is set to at the final step ().
Let us walk through what happens at a single step. Suppose we are at step , with , , , and a pixel value . The network predicts noise . We also sample from a standard Gaussian.
The denoised pixel is:
The pixel moved slightly from 0.4 to 0.408. Each step makes a small adjustment, and over 1000 steps, these small adjustments accumulate to transform pure noise into a clean image.
The full sampling algorithm can be written as:
- Sample
- For :
- Predict using the U-Net
- Compute using the update rule above
- If , set (no noise at the final step)
- Return
One important thing to note: sampling requires forward passes through the neural network (typically ). This makes DDPM sampling relatively slow compared to other generative models like GANs. Later works such as DDIM (Denoising Diffusion Implicit Models) address this limitation by enabling sampling in far fewer steps.
Practical Implementation
Enough theory — let us look at some practical implementation now. We will implement the core components of DDPM in PyTorch.
Setting up the noise schedule and forward process:
import torch
import torch.nn as nn
import torch.nn.functional as F
# --- Noise Schedule ---
T = 1000 # Total number of diffusion steps
beta_start = 1e-4
beta_end = 0.02
# Linear beta schedule
betas = torch.linspace(beta_start, beta_end, T)
alphas = 1.0 - betas
alpha_bars = torch.cumprod(alphas, dim=0)
def forward_diffusion(x_0, t, noise=None):
"""Add noise to x_0 at timestep t using the closed-form formula."""
if noise is None:
noise = torch.randn_like(x_0)
sqrt_alpha_bar = torch.sqrt(alpha_bars[t]).view(-1, 1, 1, 1)
sqrt_one_minus_alpha_bar = torch.sqrt(1 - alpha_bars[t]).view(-1, 1, 1, 1)
# x_t = sqrt(alpha_bar_t) * x_0 + sqrt(1 - alpha_bar_t) * noise
x_t = sqrt_alpha_bar * x_0 + sqrt_one_minus_alpha_bar * noise
return x_t, noise
Let us understand this code in detail. We first define a linear beta schedule from to over 1000 steps. The alpha_bars are the cumulative product of all the alphas, which gives us at each step. The forward_diffusion function uses our closed-form formula to jump directly to any noise level — no iteration needed.
The simplified training loop:
def train_step(model, x_0, optimizer):
"""One training step of DDPM."""
batch_size = x_0.shape[0]
# Sample random timesteps for each image in the batch
t = torch.randint(0, T, (batch_size,), device=x_0.device)
# Sample random noise
noise = torch.randn_like(x_0)
# Create noisy images using the forward process
x_t, _ = forward_diffusion(x_0, t, noise)
# Predict the noise using the U-Net
predicted_noise = model(x_t, t)
# Simple MSE loss between true noise and predicted noise
loss = F.mse_loss(predicted_noise, noise)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
This is the entire training procedure! For each batch of images, we sample random timesteps, add the corresponding amount of noise, and train the network to predict the noise. The loss is simply the mean squared error between the true noise and the predicted noise. That is all there is to it.
The sampling loop:
@torch.no_grad()
def sample(model, image_shape, device):
"""Generate new images by iteratively denoising from pure noise."""
# Start from pure Gaussian noise
x = torch.randn(image_shape, device=device)
for t in reversed(range(T)):
t_batch = torch.full((image_shape[0],), t, device=device, dtype=torch.long)
# Predict the noise at this step
predicted_noise = model(x, t_batch)
# Compute the denoised image
alpha_t = alphas[t]
alpha_bar_t = alpha_bars[t]
beta_t = betas[t]
# Mean of p(x_{t-1} | x_t)
x = (1 / torch.sqrt(alpha_t)) * (
x - (beta_t / torch.sqrt(1 - alpha_bar_t)) * predicted_noise
)
# Add noise for all steps except the last one
if t > 0:
noise = torch.randn_like(x)
x = x + torch.sqrt(beta_t) * noise
return x
The sampling loop starts from pure Gaussian noise and runs the reverse process for steps. At each step, the model predicts the noise, we subtract the scaled noise prediction from the current image, and we add a small amount of fresh noise (except at the final step). After 1000 iterations, we get a clean generated image.
Results and Analysis
Let us look at the results of training a DDPM on the MNIST dataset of handwritten digits.
After training for approximately 20 epochs, the model learns to generate diverse and realistic handwritten digits.

The progressive denoising process is particularly fascinating to visualize. We can see how the model gradually builds structure from nothing:

We can see that in the early denoising steps (high ), the model makes large-scale structural decisions — deciding the rough shape and position of the digit. In the later steps (low ), the model refines fine details like stroke thickness and sharpness. Not bad right?
Connection to Score-Based Models
Before we wrap up, let us briefly look at an elegant connection. It turns out that DDPM's noise prediction is intimately related to score matching from score-based generative models.
The score function points in the direction of increasing data probability — like a compass pointing toward high-probability regions.
It can be shown that the noise prediction and the score function are related by:
In other words, predicting the noise is equivalent to estimating the score function (up to a scaling factor). This beautiful connection was formalized by Song et al. (2021), who showed that both DDPMs and score-based models can be unified under a single framework of stochastic differential equations.
This means that when our U-Net predicts the noise added to an image, it is simultaneously learning the gradient of the log-probability of the data distribution. The sampling process of DDPM is essentially Langevin dynamics with learned scores. This connection is truly amazing — two seemingly different approaches to generative modeling turn out to be two sides of the same coin.
Wrapping Up
Let us summarize the key ideas of DDPM:
- Forward process: Add Gaussian noise gradually over steps until the image becomes pure noise. A closed-form formula lets us skip to any noise level directly.
- Reverse process: Train a U-Net to predict the noise added at each step. The loss is simply .
- Sampling: Start from pure noise and iteratively denoise over steps using the trained model.
- Connection: Noise prediction is equivalent to score estimation, unifying DDPMs with score-based generative models.
The elegance of DDPM lies in its simplicity — a complex generative model reduces to a straightforward denoising task. This framework has since been extended to produce stunning results in image generation (DALL-E 2, Stable Diffusion, Imagen), audio synthesis, video generation, and even molecular design.
Here is the link to the original paper: Denoising Diffusion Probabilistic Models (Ho et al., 2020)
That's it!